日本とイギリスの出生率の違い
都知事選では教育・子育てが一大関心事になっている様子。
今は選挙権がないながらも小さい子供がいる身としてはありがたいことである。
http://mainichi.jp/senkyo/articles/20160718/ddm/041/010/112000cmainichi.jp
国の経済にとっての教育・子育ての重要性
先学期のマクロ経済で学んだことのひとつがソローの経済成長モデルだ。
これは、経済成長(GDP成長)は、
資本、労働力、人的資本(Human capital)、その他(TFP)
の4つの要素の掛け算であらわされるというもの。
- 「資本」は、工場であったりコンピューターであったりビルであったり、経済活動をするための物的な道具。
- 「労働力」は、読んで字のごとく働く人×時間。
- 「人的資本」は、労働の効率性のうち、教育などヒトに関わる部分を取り出したもの。
- 「その他」は、上記以外の残りの要素の影響。
この中で、「資本」は、増やしていくとその限界効果が小さくなり、一方で減価償却が大きくなるので、 日本のような先進国ではこれを大きくすることによる経済成長は見込みにくい。
- 例えばある人がPCを持っていないときと1台持っているときの効率の差は大きいが、1台と2台は小さく、2台と3台だとほぼ変わらないに等しい。といったイメージ
そう考えると、出生率を上げて「労働力」を増やすか、教育により「人的資本」を伸ばすかしかない。
吉田松蔭の名言にもあるように、
「山は樹を以って茂り、国は人を以って盛んなり」
*1
ということで、経済的に考えても、日本の国レベルで超重要な課題なのである。
高い出生率のイギリス
と、こんなことを考えながらネットサーフィンをしているとこのような記事をみつけた。
驚くべきことに、イギリスの出生率は過去10年間で18%も上昇したとのこと。
一方で、日本の出生率は過去10年間ほぼ横ばいである。
- 日本:1.3~1.4、イギリス:1.8~1.9(World Bankより)
イギリスの出生率が高いわけ
これは日本も見習うべきところがあるのではないか?と思ったのだが、そこまで単純ではない。
上記の記事によると、出生率が伸びている最大の要因は、海外からの移民が子供を生む年頃になってきており、移民の高い出生率が全体の出生率を押し上げているということ。
日本も国内だけでの人口成長が見込めないのであれば移民を取り入れるべき!という議論もあるだろうが、これには文化、治安など単純に経済的な面だけでは語れず、日本で短期的に見習うことは難しそう。
2番目は高齢での出産が比較的容易・安全になったこと。
これだけ見ると日本でもそうだろうと思うのだが、
日本は晩婚化、出産の高齢化によって生む年齢がシフトしただけ
イギリスは20代の出産は維持したまま、30代が増えた
という違いがあるようだ。
とはいえ、イギリスは専業主婦が多いかというとそんなことはない。
ロンドンが少し特殊とはいえ、こちらは共働きが当然という感じで、
「your wifeは何の仕事をしているんだい?」と聞かれることもしばしばである。
実際下記のデータで見ても、女性の経済参加率でイギリスは18位、日本は100位以下である。
イギリスの出生率が(移民の影響を抜きにしても)高いこと、上がってきていることの要因は大きく、
労働市場の流動性
子供ウェルカムなインフラ
の2つだと思う。
労働市場の流動性
日本の終身雇用・年功序列の中では、いかに「産休」「育休」が充実しようが女性にとって働くことは難しい。
大きい会社になればなるほど、同期入社の間で出世競争があり、会社側、女性側共に、「産休」「育休」は事実上のドロップアウトと感じやすいのではないか。
イギリスはもっとスキルベースのキャリア作り。
休んでいようが何していようが、「こういう経験を何年積んで、こういうスキルがあります」と言えれば採用されるし、
そのように考えて皆が自分のレジュメを意識しながら「マーケティング」なり「人事」なりキャリアを積んでいるように見える。
日本も今後10年~20年でこの辺りは大きく変わっていきそう。
子供ウェルカムなインフラ
ロンドンに生活していると、子供に優しいなと思うポイントが多い。
日本に比べてもそうだが、この前行ったパリに比べても圧倒的にそう思った。
例えば物理的な面では、
- 多くのレストランに子供用のハイチェアがある
- バスに大きなベビーカースペースがある
- 歩道が広く(かつ地形的に坂道が少なく) 、ベビーカーで動きやすい
ソフトなインフラという意味では、
- 無料の赤ちゃん・子供向けアクティビティーが至るところで開催されている
- 18歳以下は病院・薬全て無料(これは日本でも自治体によってそうだが)
- 個人でナニー(保母さん)を雇うことが一般的
また、上記とあわせて、心理的な意味では、
- 赤ちゃんを見ると皆優しい。老若男女問わず、ニコニコして話しかけてくれる
- 電車やバスでは若者が必ず席を譲ってくれる
日本での育児経験がないので、公平な評価かどうかはわからないものの、
こういった要素全てが織り合わさって皆が、「子供を産もう」という気になりやすい環境が作られていると感じる。
日本では、子育てといえば待機児童の問題ばかりが取り上げられている印象。
もちろん待機児童の問題は重要だし、保育園は充実してもらわなければ困るけれど、
「保育園作ったらそれで子供増えるでしょ」という考えは甘いのではないか。
それ以外の要素も合わせて、新しい都知事にはより「子供に優しい東京」を期待したい。
*1:あまり知らなかったけど、吉田松陰の名言は良いのがいっぱいある。さすが教育者。
bakumatsu.org
ラマダーンと昼の長さ
しばらく間隔が空いたが、元気に更新して三日坊主の懸念を吹き飛ばしたいと思う。
さて、今日は日本では七夕だが、昨日7月6日はイスラム教徒にとっては非常に重要なラマダン明けのお祭り、イードであった。
(ラマダーンは太陰暦で決まるので、毎年少しずつ日付はずれる)
僕もラマダーンはなんとなく知っていたが、ラマダン明けの日に祝祭があること、それが一年でも最も宗教的に重要な日の1つであること(つまりキリスト教でいうところのクリスマスみたいなもの)ということは全く知らなかった。
改めて日本はイスラム教とは縁遠い国だなぁと感じると共に、こちらにきて随分身近になったと感じる。
特に最近テロ事件が続いており、日本では、イスラム教→テロ、のようなイメージがついてしまっているかもしれないが、テロリストはイスラム教の中でも異端であってイスラム教徒も大部分は普通にいい人だよ!ということは強調しておきたい。
ラマダーンは、「日の出ている間は水や食物を口にしてはならない」というもの。
6月といえば、北半球の大部分では一年のうちで一番長い月、
しかもロンドンは緯度が高くて特に日が長い、
ということでここに住んでいるイスラム教徒は今年は大変である。
(特にここで生まれ育ったわけではない留学生などからは、「勘弁してくれ!」という声を聞いた)
ロンドンは、夏は日が長く、冬は日が短い、とよく言われるし、自分でも身を持って体感する。
でも具体的にどれくらい違うのか?どの程度が緯度によるもので、どの程度はサマータイムによるものなのか?
が気になったので、調べてみた。
プログラミング言語とサーバーの勉強も兼ねて簡易WEBアプリを作って(*1)プロットしてみたものが以下。
(日の入り、日没の時刻は、緯度、経度と日付から久々に使う三角関数で求めているが、地球が真球であると想定していたり、一日の中での公転の影響を無視していたりするので、10~20分程度ずれている可能性があるのであくまで参考値)
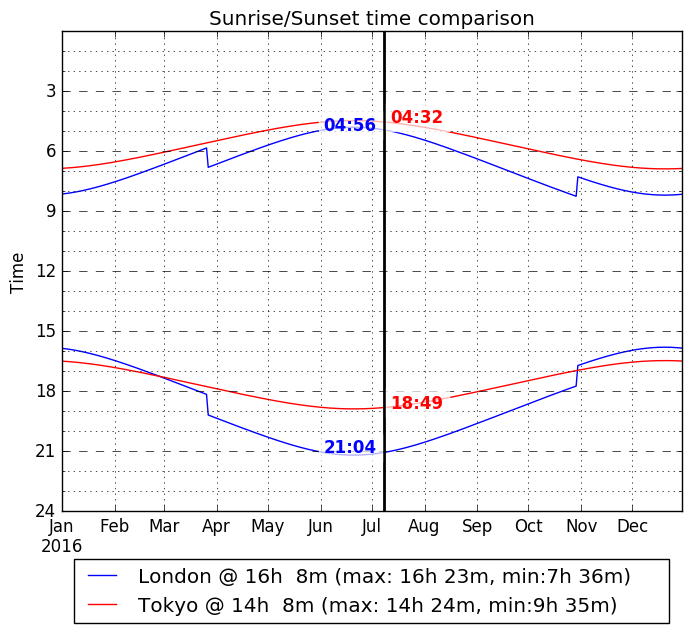
ラマダーンの最長時間は4時半過ぎから21時半前までである。これは確かに大変そう。。。
東京と比べてみてもやはり夏場の日没時刻の違いは明白。2時間以上も差がある。
日の出はそこまで変わらないので、昼の長さはちょうど2時間程度の差である。
これを対東京で朝1時間、夜1時間増とする代わりにサマータイムで夜2時間増にしているイメージ。
冬に目を向けてみると、冬のロンドンはすぐ暗くなるというイメージがあったが、日没の時間としてはそこまでの差ではない。
せいぜい40分程度か。
それ以上に日の出の時間の差の方が大きい。
冬場は1限の授業があるときは7:30に家を出て、暗いなーと気分が滅入っていたが、このグラフを見ても明らかである。
さて、ラマダンに話を戻そう。
イスラム教は厳格な宗教と思われている(し、実際そういう部分も多い)が、ラマダーンに関しては意外にフレキシブルなところもあるというのが個人的には面白かった。
子供や老人は強制されなかったり、病気、生理の場合は時期をずらしたりということも許されている。
また、白夜やそれに近い日がある北欧ではどうするのだろうと思ったら、居住国の時間ではなく、メッカ時間に則ってラマダーンをする人もいるらしい。
先ほどのWEBアプリで同様にメッカとロンドンの比較を見てみると以下のようになる。
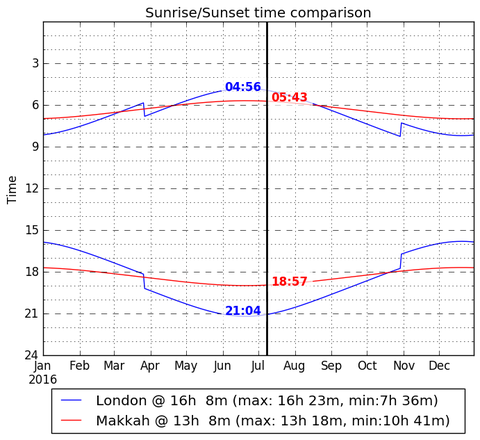
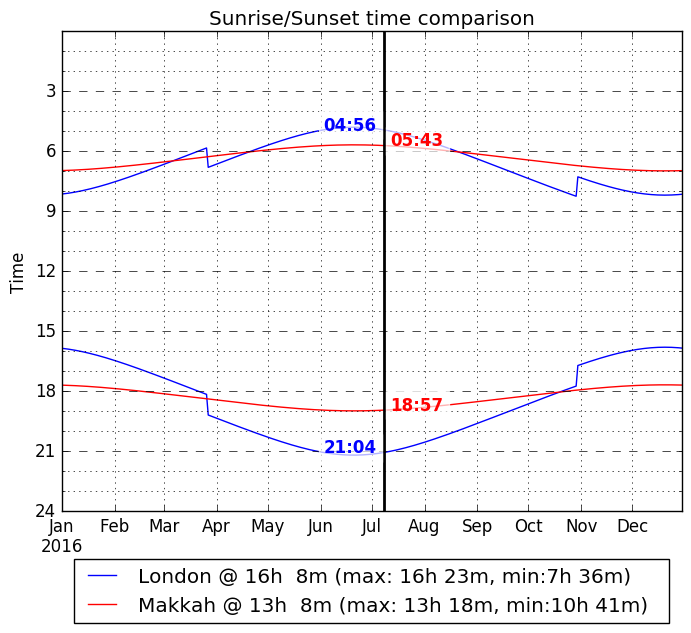
なるほど。メッカ時間であれば、ラマダーンがどんな季節になろうが変動は少ない。
朝6時から夜7時くらいなら、まぁなんとか耐えられなくもないかなーと思う。
やはり、イスラム教は中東を中心として赤道に近い国々で生まれ、信仰されているからこそ、「日が出ている間は飲み食いしない」というしきたりが成立したんだな、
と、地理と宗教の結びつきを感じた一月であった。
*1 サーバーの設定など質問攻めに根気強く対応してくれた友人に感謝
価格から考える日本とイギリスの違い
さて今回は原点に戻ってMBAっぽいお話。
最近は随分慣れた(&為替でポンドが安くなった)が、ロンドンに来てしばらくは物価が高くてやってられないと感じていた。
振り返って考えると、実際に高いというのも勿論あるのだが、価格設定の考え方が日本と違うためによりそう感じられた部分もあるのかなと思う。
今回はロンドン買い物あるあるから、その背景にある考え方の違いを見てみたいと思う。
Case 1. ボリュームディスカウントの感覚が違う
スーパーの500mlペットボトルジュース売り場でよく見る表示
1個で1.5ポンド(約225円)、2個で2ポンド(約300円)
いや、1個買うの馬鹿らしすぎるでしょ。。。
ステーキハウスのセットメニューの価格
300gで20ポンド(約3000円)、500gで36ポンド(約5400円)(肉の部位は同じ)
いや、大きいののお得感ないどころか損なんだけど。。。
ここからの気づくことは、
日本人は値段を考えるとき原価をベースに考えることが多い、
イギリス人は、消費者の支払意思をベースに考えることが多い ということ。
1個目の例で言えば、
例えば仕事の休み時間に寄って今すぐ飲みたい!と思っているお客さんは高かろうが1個買うし、逆に高くても安くても2個は買わない。
一方で普通に買い物に来ている主婦は、家に帰ってから飲むから、高かったら買わないor他のスーパーで買っちゃう。まとめ買いする可能性も高い。
こう考えると1個は高く、2個は安く、というのは非常に理にかなった価格差別の方法である。
(買い手が異なる支払意欲を持っている時、それにあわせて価格差別を行うことで企業は利潤を最大化できる。この時支払意欲が高いグループが低い価格で買ってしまうのを防ぐことが上手い価格差別のコツ)
2個目の例についても、
ボリューム増やしたいと思ってる人は、「今日はお金のことは気にせずがっつりいくぞ!」って気分の人だから、高めに設定しても払うだろう、という考え。
あとはイギリス人の方が算数が苦手だから損だと思いにくいというのもありそうだけど 笑
もう一段深く考えてみると、
日本の方が小売の競争が激しい
ということが言えるかもしれない。
ミクロ経済によれば、完全競争の下ではモノの価格は原価に一致し、
(例えばガソリンスタンドのガソリンなどはこれに近い)
その逆の独占の場合は顧客の支払意欲に一致する。
(例えば野球スタジアム内の売店のビールやアイスはこれに近い)
これに最初の例を当てはめて考えると、
日本は完全競争の近く、イギリスは独占に近いと類推される。
特に1個目のスーパーの飲み物の例はこれでかなり説明できると思う。
日本では、もし今飲み物を飲みたい!という人がスーパーに入って馬鹿高い500mlボトルを見たら、買うのをやめて近くのコンビニか自販機で買うだろう。
コンビニが日本の小売における競争環境のベースを形作っていると言っても過言ではない。恐るべしコンビニ。
(いや、ほんとにイギリスに来るとコンビニの有り難みを身にしみて感じます)
もう1つの説明は、
イギリスは目先の利益重視、日本は長期的な利益を重視
ということ(意識的にというわけではないと思うが)。
例えば最初の例でスーパーが高い価格で飲み物を売ったとする。
今すぐ飲みたい人はこれを買うかもしれないが、この人は「この店は高いな」という印象を持つ。
そうすると次回普通の買い物をしようという時にこのスーパーを選ばなくなるかもしれない。
そう考えると、短期的には高い価格で売った方が良くても、長期的な目線で考えると必ずしも高い価格で売ることが店側のメリットになるとは限らない。
こういった感覚が日本企業の方が強いのではないだろうか。
Corporate Strategyの授業でこんなことを学んだ。
「欧米人に比べて、アジア人は全体論的に(holistically)考える傾向がある」
例えば、ソニーの家電が品質が高いと、ソニー銀行のサービスも品質が高いと思う、
イチローがスポーツ選手として一流なので、政治家としても一流になるんじゃないかと思う(首相になって欲しい人ランキングに登場する)
などなど、ある事象から類推する範囲が広いということ。
だから、スーパーである1つの商品が高いと、「他も高いんだろうな」という類推が働きやすいのだと思う。
Case 2. 思わぬところで追加料金を取られる
フォートナムメイソン(紅茶屋さん)にて
僕「プレゼント用なのでラッピングしてもらえます?」
店員さん「ラッピングは別コーナーで承っております。プラス5ポンド(約750円)かかります」
僕「(うわ、高いな。。。)」
ドトールコーヒー的な喫茶店にて
僕「このサンドイッチください」(3ポンドを出す)
店員さん「店内でお召し上がりですか?プラス1ポンドで4ポンドになります」
僕「(あ、店内と持ち帰りで値段違うのね。。。)」
レストランで食べたあと
店員さん「こちらお会計になります」
僕「(なんか思ったより高いな。あ、12.5%のサービスチャージ乗せられてる。お金取れるようなサービスされた記憶ないけど。。。)」
ここからわかることは、
日本はモノに対してお金を払っている意識が強く、サービスに対してお金を払っている意識が弱い
ということ。
イギリスでは、
ラッピングはそれに対して追加で人が作業しないといけないから当然追加料金
料理の値段は料理の価値(材料とかコックさんとか)に対するもので、ウェイターや場所代はサービスチャージとして別に請求
ということで、サービスに対価を求めることが当然。
対して日本では、
サービスという日本語が、よく「これサービスしとくね」という風に使われることからも伺えるように、サービス=無料という意識がある。
対して日本では、
サービスという日本語が、よく「これサービスしとくね」という風に使われることからも伺えるように、サービス=無料という意識がある。
一消費者としては日本の「サービスは値段のうち」というのはわかりやすいし、日本のサービスの質は軒並み高いから嬉しいけど、働き手の意識としてはイギリスに見習うべき点も多いと思う。
日本人の生産性が低いということが最近言われているが、
「我々の労働(時間)は付加価値を高めるものに対して費やされるべき」
という考えが浸透してないことが、過剰品質や無駄な残業の増加に繋がっているのではないか。
また、それを働き手側が意識しなければ、消費者側も、「これくらいタダでやってくれて当然」という感覚が抜けないと思う。
まとめ
MBAのクラスメイトに、
「ガリガリ君の値上げのCMをYoutubeで見たよ。数十年間値上げせず、60円から70円にするだけであの騒ぎってcrazyだな!」
と言われた。(日本人以外が知っていることにびっくり)
「ガリガリ君の値上げのCMをYoutubeで見たよ。数十年間値上げせず、60円から70円にするだけであの騒ぎってcrazyだな!」
と言われた。(日本人以外が知っていることにびっくり)
個人的には、ガリガリ君は皆から愛されている素晴らしい商品だし、作っている赤城乳業の姿勢も日本企業らしくて良いなと思う。
でも、この例からわかるように、日本人は値上げに対して敏感すぎるし、そのせいでついついコスト削減の方に目が行きがちになっていると思う。
コスト削減もいいけれど、日本は新興国より人件費は高いし、人口が減少していく中で売る量を増やすということも望みにくい。
だからこそ「どうやったら顧客からより大きな対価をもらえるか」という観点で、付加価値を上げて、値段を上げて、ということをもう少し考えていくべきだと思う。
(そうすると自然と消費も活性化されて経済も活発化するはず)
子供の成長と70の法則
今日うちではこんな会話が行われた。
僕「いやー、最近うちの子の成長は著しいね。今日一日で3%くらいは成長したんじゃない?」
妻「えー、3%ってほんのちょっとじゃん」
僕「3%を舐めちゃいけない。毎日3%ずつ成長したら何日でもとの2倍になると思う?」
妻「えーっと、、、 (中略)
1.03の2乗は1.0609、うんだいたい1.06だ
1.03の3乗は1.092727、うんだいたい1.09だ
1.03の4乗は1.12550811、うんだいたい1.12だ
だから1日経つと0.03ずつ増えるから、2倍になるのは1/0.03=33.333... よりちょっと短い1ヶ月くらい!」
というのがしばらく頭を捻った妻の回答。
僕「筋は悪く無いんだけど、これだと複利が全く考慮されてないから、成長率が大きくなったり、期間が長くなったりするほど正確じゃなくなる。1.03の30乗は2.4くらいになっちゃう。もうちょっと精度を上げてみよう。
rを1日の成長率(上の例で言うと3%)、
初期値をA0(今日の息子)、
n日後の状態をAn(例えばA2は二日後の息子)
としてみよう。
例えば四日後はどうなる?」
妻「それくらいならできそう。 えーっと、
二日後は A2 = A0 * (1+r)2 = A0 * (1 + 2r + r2) でしょ?
同じようにやると、三日目と四日目はこんな感じかな?
A3 = A0 * (1+r)3 = A0 * (1 + 3r + 3r2 + r3)
A4 = A0 * (1+r)4 = A0 * (1 + 4r + 6r2 + 4r3 +r4) 」
僕「ということは、n日後はどうなる?」
妻「むむむ。 それはわかりませぬ。」
僕「こんな感じになるよ。
An = A0 * (1+r)n = A0 * (1 + nC1r + nC2r2 + nC3r3 ..... ) 」
妻「うーん、はるか昔に見たような。。。なんでnC1とかになるんだっけ?」
僕「(1+r)nは、(1+r)(1+r)(1+r)... の、それぞれのカッコから、1かrを選んで掛けたものの全ての組み合わせになる。
例えば、nが3のときだったら、こんな感じ。
1*1*1
1*1*r
1*r*1
1*r*r
r*1*1
r*1*r
r*r*1
r*r*r
これを全部足すとさっきの1 + 3r + 3r2 + r3になるね。」
妻「ふむふむ」
rの項は、n回のうち1回だけr、残りは1をかけるパターンだから、n通りある。
raの項は、n回のうちa回rを掛けるってことになるから、nCaだよ 」
妻「なーるほど」
僕「rが1に比べて小さいから、rの乗数が大きくなるほど項の値は小さくなる。
r2の項から先を全部無視すると最初の答えになるよ。
(1+r)n ≒ 1 + nr
今回はr2の項まで残してみると、
(1+r)n ≒ 1 + nr + (n(n-1)/2)r2
これが2倍になるnだから、
A0 * (1 + nr + (n(n-1)/2)r2 )= 2A0
(n(n-1)/2)r2 + nr - 1 = 0
(n2-n)r2 + 2nr - 2 = 0
ここでr2はnに比べて小さいから、簡単のために最初の-nの部分を無視するとこうなる。
n2r2 + 2nr - 2 = 0 」
妻「そろそろお風呂に入ってきてもよろしいでしょうか・・・」
僕「もうちょっとだけ!
2次方程式の解の公式よりrを解くと、
r = (-2n + √(4n2 + 8n2)) / 2n2
r = (-n + √(3n2)) / n2
r = (√3 - 1) / n
これをnの式に変形すると
n = (√3 - 1) / r ≒ 0.73/r
ということで、最初に戻ってrが3%のときは24日くらいで倍になる!
実際に1.03の24乗は2.03なので悪くない精度でしょ 」
妻「おぉ! rが変わっても同じ式が使えるのがすごい!」
僕「そう、実はこの考え方は経済の授業なんかでも出てきて、70の法則って言うんだよ。
「年率r%の複利で成長すると、元の2倍になるまでにかかる年数はだいたい(70/x)年」
てこと。例えば
- 年率1%なら70年で倍
- 年率2%なら35年で倍
- 年率5%なら14年で倍
- 年率7%なら10年で倍
といった感じ。利息の計算や、GDP成長を考えるときに便利。」
妻「へぇ。経済はよくわからないけど、70の法則は面白いね!」
僕「ちなみに参考までにザ・数学的な導出はもっとシンプルで以下のようになるよ。
(1+r)n = 2
n * ln(1+r) = ln2
n = ln2/ln(1+r)
rが小さいとき ln(1+r)≒r なので(テイラー展開)、
n ≒ ln2/r = 0.693.../r ≒ 70/(100*r)
でも直感的じゃないし、2の自然対数なんて普通知らないからさっきの方法の方がわかりやすいでしょ?」
妻「??? うん、それはいいや。。。」
ちなみにスペースの関係で端折ったけど、妻は算数を真面目に考えるのが久しぶりすぎて、
途中「解の公式、、久しぶり過ぎて忘れた!」「頭がオーバーヒートする!」などとてんやわんやでした。
おかげで図らずも子供に算数を教えるイメージトレーニングになったような。
でも確かに解の公式を始め、数学の公式なんて一部の職業以外だとほとんど使わないもんなー。
でもそれ以上に「古文・漢文」なんて、実用的にも教養的にも学校で勉強する意味合い小さいよなー。
などと思った週末でした。
EU離脱とトリレンマとナショナリズム
いつの間にか自分が全く詳しくない政治やマクロ経済について書くブログと化している。
留学がこういうことを考えるきっかけになるとは。
さてさて、イギリスの国民投票はEU離脱の勝利。
意外である。直前は残留派が盛り返していたし、賭けサイトのオッズも残留優位だったので、
なんだかんだ最後は残留に転ぶだろうと思っていた。
トランプ氏の台頭や今回の結果に思うのは、グローバル化の反動とも言える世界的なナショナリズムの台頭である。
残留派が勝利した主な理由は2つ。ひとつが勘違い、ひとつは国民性である。
まずは一つ目。経済的な観点。
今回の争点のひとつが移民問題。「移民がEUから大量に押し寄せてきて英国民の仕事を奪う」的な主張であるが、これは説得力に欠ける。
移民が来ることによって新たに消費も生まれる。彼らが消費をすることは国内で新たな仕事が生み出されることを意味する。
しかも、海外に仕事が奪われるのは今の時代人の移動を伴う必要がない。
製造業が日本やアメリカから中国やその他アジアに大きく労働力をシフトしたように、
その国の労働競争力が低ければ移民がいようがいまいが仕事の喪失は起こるのである。
特に低所得者層がこの危惧を持っているが、このあたりについての勘違いが解消されなかったのが一つ目の理由だろうと思う。
この問題を含め、経済的な観点では、雇用、投資、貿易どの側面を見ても残留が好ましい材料が多い。(LBSの教授であるAlex EdmansのBlogの以下のポストがよくまとまっている)
そこで出てくるのが二つ目。経済を超えた国民感情である。
米国のトランプ氏の状況と少し異なるのは、この国では「短期的には経済的にマイナスであることは分かっていても英国の独立性を保つために離脱するんだ」という層がそれなりにいること。
通貨としてユーロを採用せずポンドを使い続けてきたことからもわかるように、彼らは「独立性」に対する執着が強い。
(本部が全て大陸にある)EUに自分たちの運命を決められてたまるか!というのが彼らの思いなのだろう。
先学期のマクロ経済で「国際金融のトリレンマ」を学んだ。
トリレンマとはジレンマ(2つの物事の間で板挟み)の3つ版であり、経済においては、
- 為替の安定性
- 自国の独立した金融政策
- 国家間の自由な資本移動
の3つを全て同時に満たすことは不可能である(2つを取ると1つを諦める必要がある)という理論である。
EUはEU圏内での為替の安定性(共通通貨)と自由な資本移動を可能にした代わりに、
金融政策はEUの単位でしか行えず、国単位では金利の上げ下げや量的緩和をコントロールできないというトレードオフがあった。
すると、国単位では比較的効率の悪い財政政策(政府の収入支出の変動)だけで経済問題に対応しなければならない。それを嫌ったのが今回のイギリスの選択である。
中~高所得者層でも保守、高齢者の層が離脱側についたのはこのような考えからであろう。
ここで、両方に共通して言えることが、「国内での不満蓄積」と「国外への責任転嫁」である。
格差社会という言葉が日本でも聞かれるようになって久しいが、世の中の富の偏重はここ2、30年で激しく進んでいる。
アメリカでは上位1%が全国民の収入の20%を稼いでおり、過去10~20年でその比率は倍以上に膨れ上がった。
そうすると、国全体でのGDPは成長していても、大多数の国民にとっては変わらない或いはより貧しくなっているように感じられるのである。
そこで出てくるのが国外への責任転嫁。
当然政治家は1%からの票だけでは食べていけないので、99%を納得させる必要がある。
そこで、低所得者層の不満(給料が上がらない、失業率が上がるなど)を、移民のせい、EUのせいにするのである。
99%の人たちに言いたい。違う。それらの殆どはあなた達自身や、あなた達が選んだ政治家によるものだと。
日本人は自分も含めて政治に対する関心が低く、そういう意味では危険性が高い。
ちゃんと情報も集めず、投票にも行かず、結果悪くなった時に国外に責任転嫁をするような国民にはなってはいけないなと思った。
===================================
閑話休題。最近友人に勧められ、2008年の金融危機の原因をドキュメンタリー化したInsider Jobという映画を見た。
この映画を見るとアメリカ嫌い、金融嫌いになること請け合いである。上に書いたこともそれを見た影響が出ているかもしれない。
簡単に言うと、
- アメリカの金融関係の国の主要ポスト(FRB、SEC、大統領補佐など)は元投資銀行のトップ層で構成されているため、政治家は投資銀行が有利になるように制度を作っているし、投資銀行がピンチになったらそれを救済する
- 投資銀行は一般人には難しいスキームの金融商品を設計し、リスクが高いものをさも安全なように詐欺的に売りつけていた。格付け機関も投資銀行からお金を得ているのでそれに加担
- 極めつけに、投資銀行はそれが安全じゃないことを知っているので、その金融商品が不払いになったときにお金が入ってくるような逆向きの保険を大量に購入していた
(この山は安全だから登って大丈夫ですよ、と危険な山を勧めながらその人に生命保険をかけて自分が受取人になってる人みたいな感じ)
あぁ思い出すだけでも虫唾が走る。
ドナルド・トランプに見るコモンズの悲劇
今年は世の中を賑わす選挙が多い。イギリスのEU離脱、アメリカ大統領選、ペルー大統領選などなど。日本にいるときは殆ど政治にアンテナを張っていなかった僕も、ここに来て少しフォローしている。
今回はトランプ氏の大躍進から思うこと。
多くの世論と同じく、僕もトランプ氏がここまで票を集めて党の候補になるなんて思ってもいなかった。しかし彼の公約を見ると、なるほどよく票が取れるように練られている。例えば、、
- 年収2万5000ドル未満の単身世帯と年収5万ドル未満の夫婦世帯は所得税を免除する → 低所得層獲得
- 銃所持の権利守る → 軍需産業獲得
過激ながら十分にマスが取れそうなところをターゲットにしている。
さすが実業家だけあってマーケティングが得意と言うべきだろうか。
もう1点の特徴は、徹底的に国内の利益を重視し、選挙権がない海外や移民には徹底的に厳しい政策を打ち出しているところ。
- イスラム教徒に対する米入国一時禁止を呼び掛け、シリア難民は受け入れない
- 中国、日本、メキシコ、ベトナムおよびインドに対し、自国通貨を下落させ米国からの輸入品を排除することで米国から「略奪している」と非難
- 中国は通貨を操作していると指摘し、同国の輸出品には相殺関税を課す方針。政府による輸出業者への助成制度を世界貿易機関(WTO)に訴える意向
- オバマ政権下の環境規制を撤廃し、2020年以降の温暖化対策の国際的枠組み「パリ協定」の合意を取り消す
有権者の利益を重視するのは政治家として当たり前といえば当たり前なのだが、特に最後のなどは気になる。
環境問題などは往々にして、各自が自分の利益を最優先すると全体最適ではなくなるという問題を抱えている。
- 二酸化炭素いくら排出しても、個々の個人、企業や国に対する影響は短期的に見ると限定的。しかも自分が出さなくても他の人が出したら結局同じような悪影響が出るから抑制するインセンティブが働かない
(いわゆる経済でいうコモンズの悲劇)
これをどうやって回避するのか?
まず考えられる直接的な手段は「教育」。
例えば移民の強制退去は表面的には国内の離職率を下げる役割を果たしそうだが、 人手不足が起きて、2年間でGDPの2-3%が失われるとの試算もある。
マクロな視点で考えればアメリカ自身にとっても決して最適な選択ではないということを伝え、そのような政策に投票しないように呼びかける。
とはいえ、国民全員にそういう視点を持たせるのもなかなか難しそうだし、今の選挙の状況がその限界を物語っている。
では企業の例を参考にしてみてはどうか。
企業で考えると、国の介入と市場原理の2つの抑止力がある。
前者の典型が廃ガス規制だったり、タバコ税(これは単純に税収の意味もあるけれど)。
でも今回のトランプ氏のように国単位でそれをやられた場合、なかなか抑止する方法がない。
小国であれば、国連の経済制裁などの手段があるが(核開発を表明した北朝鮮に対する経済制裁など)、アメリカほどの大国になると国連も手の出しようが難しい。
後者の市場原理は株主を通じた制裁である。
CSRが注目を浴びるようになり、利益を出していても社会に対してネガティブな影響を与えていると思われては企業価値が下がるという傾向はここ10年ほどで随分強くなったと思う。
(VWや三菱自動車がここまで打撃を受けたこともその表れだろう)
国には社会の代理人として監視する「株主」が直接はいない。
だとすると、その役割を担えるのは日本であったりイギリスであったり海外の国々に住む人々だろう。
というわけで、アメリカ人ではない我々にも、このアメリカの動きをフォローし、もし社会にネガティブな動きをするようであれば声を上げていくべきである。
我々の声が国の政治家を動かし、対アメリカの姿勢を変えれば、アメリカだって無視するわけにはいかないはず。
なんて素人ながらに考えていた。
きっと公共政策大学院とかはこういうことを勉強、議論しているんだろうな。
AIと私 part 1
最近ちまたでは人工知能ブームである。
僕もミーハーながら今年の始め頃から注目している。
メディアで取り扱われることも最近は多いが、僕が興味を持った直接的理由は以下の2つ
- GoogleのAlphaGOがトッププロ棋士に勝った。(なんちゃってではあるが)囲碁をちょっと齧っていて、コンピューターとトッププロにはまだまだ差があると知っていただけに衝撃が大きかった。
- ちょうど子供が産まれ、子供が新しいことを学んでいくのを目の当たりにして、人工知能が学習する過程が非常に身近かつ興味深く感じられた。
まだ関連する本を2、3冊読んだ程度の素人なので見当違いのこともあるかもしれないが、いま時点での理解と考えていることを少し書いてみたいと思う。
人工知能の定義
人工知能を定義することは実は意外と困難で、世の中での使われ方も、時代によっても変わるし、今だけで見ても定まってはいない。
僕の理解では、①人間にしかできなそうなことを②人間と同じような思考回路で行うコンピュータということかなと思う。
前者に関しては、例えば以前はOCR(紙に書かれた文字を認識してデジタル化すること)が人工知能だと言われていた時代もあったらしいが、今ではOCRは機械ができることが当たり前になって誰も人工知能だとは呼ばない。
後者に関しては、例えばオセロやチェスで人間に勝っても、全通りの可能性を虱潰しに探索して打ち手を見つけるのでは人工知能「っぽくない」。
最近流行っている理由
他にも色々あるのだろうが、とりあえず以下の2つが大きいようだ
- ディープラーニングという手法の確立
- 学習のためのデータ取得のハードル低下
一点目のディープラーニングという手法はニューラルネットワークの一種で人間の思考回路に近い(ように見える)ので、前述の「人間と同じような思考回路で」という部分に引っかかって人々の琴線に触れているのだと思う。
ディープラーニングと従来の機械学習の違いをとても大雑把にまとめると以下のような感じだと思う。
これまでの機械学習
- インプットは主に人間が構造化したデータ。何のデータを使うかは人間が予め選択
- 例えば顧客が不払いを起こしそうか?ということを判断するためには、年齢、年収、職業、住んでいる地域、等をデータとして与えるが、「髪型」はデータとして与えない
ディープラーニング
- インプットは人間が構造化してない(人間の恣意性が入っていない)「生」のデータ
- 画像(色つきのドットの集合体)、音声(波形のデータ)など
- 学習の過程で自分で判断のための特徴を抽出する
- 例えば画像に猫が写っているかを判断するために、「耳の形」、「眼の色」、「ひげがある」、などが手がかりになるということを自分で学ぶ
二点目については言わずもがな。特にディープラーニングの活用が画像認識と音声認識で進んでいるのは、ひとえにインターネット等のデジタル媒体で画像と音声の生データが容易に大量に手に入るからだと思う。
何に使えるのか
ディープラーニングが人間と同じようなインプットと思考回路を使うということからして、人間が今やっていることを代替するというのが素直な発想。
特に、学習の範囲が狭くて明確な方がコンピューターが相手しやすいので、専門的なことの方がやりやすそう。
「これまでの機械は主にブルーカラーの仕事を代替してきたが、AIはホワイトカラーの仕事を取ってしまう」と言われているのはこれがゆえ。
例えばコールセンターやCT等の画像からの病気の判断、弁護士の業務なんかは随分AIが活躍しやすそう。
個人的今後の注目ポイント
今人間がやっている「処理」の部分がAIにとってかわられるとすると、機械に学習のタネを提供することの重要性が増しそう。
例えば研究的なところでいうと
- 人間には5感がある。視覚、聴覚以外の情報(味覚、嗅覚、触覚)をどういう形で表し、どうやって蓄積していくのか
- 味覚DBができたら、食品メーカーは美味しいものをもっと体系的に作れるだろう
- 5感は独立していない。音声と画像などのマルチモーダルな情報をどのように組み合わせて学習させていくのか
- 美味しい料理の判断は5感の組み合わせ。猫を認識するためには姿だけではなくて鳴き声も重要
などが気になる。
もう少しビジネス寄りのところで言うと、今企業では以下のようなことを考えているが、
- 自社の業務のどこを内製すべきか、どこは外注(例えばインドのIT企業にとか)すべきか
- 工場でどの部分はオートメーションにして、どの部分は手作業でやるべきか
これと同じようなレベルで
- どの部分はAIに任せ、どの部分は人を雇ってやるべきか
といった議論が行われるのもそう遠い話ではないのではないかと思う。
20年後にはCorporate Strategyの授業でAIに関するケースが出てきてもおかしくない。
あとは月並みだけど変革期にはビジョナリーが求められる。
今人がやっていることの代替とだけ言うと大した変化がなさそうだが、そんなことはない。
あることのコストが20%減っても業界はそんなに変わらないが、1/10、1/100になると根本からビジネスモデルが変わる/生まれ得る。
- 携帯の費用対通信速度が圧倒的に上がったことでスマホという存在ができた
- もし宇宙飛行のコストが1/100になれば宇宙旅行は一つの産業になるだろう
- AIで通訳ができるようになれば、これまで1時間万円単位でかかったものが変動費ほぼ0でできる。インパクトは通訳業だけでなくインターナショナル企業のあり方や国と国との関係にまで影響するだろう
こういった変化を予期し、創造していくことはコンサルという立場でも重要になってくるのではないか。
ということでもう少し継続的にAIについてはフォローしていきたい。